
Trước tiên, hãy tìm hiểu về Big Data, Machine Learning, Trí tuệ nhân tạo và Deep Learning thật sự là gì nhé:
Big Data là gì?
Big Data là một phương thức thu thập một lượng dữ liệu từ một hoặc nhiều nguồn. Từ đó, dùng dữ liệu để phân tích và đưa ra những giải pháp phù hợp nhất đúng với ngữ cảnh. Những tập dữ liệu lớn này có thể bao gồm các dữ liệu có cấu trúc, không có cấu trúc và bán cấu trúc, mỗi tập có thể được khai thác để tìm hiểu insights của khách hàng cũng như người dùng.
Có ba thành tố Big data thường đặc trưng
- Khối lượng dữ liệu: doanh nghiệp và tổ chức thu thập dữ liệu từ nhiều nguồn, gồm các giao dịch, social media, các kênh marketing truyền thống cũng như những kênh phổ biến và không phổ biến khác.
- Nhiều loại dữ liệu đa dạng: Dữ liệu đến từ nhiều nguồn, nhiều dạng, hình ảnh, email, audio, cookies, số điện thoại, địa chỉ, điền form, các giao dịch online, v.v
- Vận tốc mà dữ liệu cần được xử lý và phân tích để đáp ứng được nhu cầu sử dụng và tương tác với dữ liệu của tổ chức.
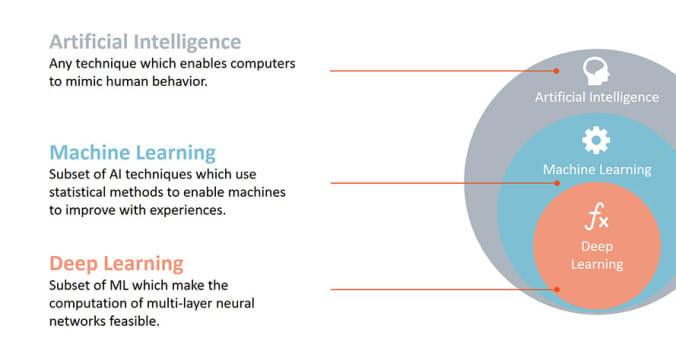
Liên hệ giữa Trí tuệ nhân tạo, Machine Learning và Deep Learning
- Trí tuệ nhân tạo (AI): Là tên chung của lĩnh vực liên quan đến việc xây dựng các hành vi thông minh cho máy móc.
- Machine Learning: Là một phần thuộc trí tuệ nhân tạo, sử dụng dữ liệu để tạo ra AI.
- Deep Learning: 1 phương pháp của Machine Learning tiếp cận một dataset lớn.
Với cách hiểu này, chúng ta hãy cùng khám phá danh sách ngày hôm nay nhé:
Các công cụ và kỹ thuật hữu ích trong Big Data
Athena
AWS Athena là một dịch vụ được dùng để truy vấn trực tiếp các file trong S3 bucket bằng cách “dùng tới đâu, trả tới đó.” Sẽ dễ dàng để truy vấn data ở nhiều format khác nhau mà không cần phải sử dụng công cụ ETL để load nó trong database.
Dịch vụ này cũng có thể được sử dụng riêng, tích hợp với AWS Glue như là một Data Catalogue hoặc tích hợp với AWS Lambda như là một phần của cấu trúc lớn hơn.
Batch Processing (Xử lý hàng loạt)
Dự án Big Data phụ thuộc vào khả năng Data Scientist có thể xử lý terabyte hay petabyte của data. Các công cụ như Apache Flink có thể giúp bạn hoàn thành công việc sử dụng các dòng data hoặc xử lý hàng loạt.
Compute
Cần phải có các cơ sở hạ tầng để các Data Scientist xử lý các tập Data lớn. Chúng ta có thể sử dụng tự động hoá để đảm bảo có đủ khả năng xử lý khối lượng data.
Để việc quản lý AWS dễ dàng hơn, mình xin giới thiệu với các bạn công cụ Predictive Auto Scaling, sử dụng Machine Learning để mở rộng quy mô tính toán các tài nguyên hỗ trợ Machine Learning.
Docker
Việc chia sẻ kết quả của các thí nghiệm khoa học dữ liệu chưa bao giờ là dễ dàng cả. Các hệ điều hành và các thư viện R không phải lúc nào cũng tương thích tuỳ thuộc vào người bạn đang chia sẻ. Tính bảo mật cũng là một vấn đề khi chia sẻ các bộ Data và dashboard cuối cùng giữa những người dùng.
Và đó là lý do Docker ra đời. Các Data Engineer có thể cung cấp cho Docker những hình ảnh “đóng băng” hệ điều hành và các thư viện để các sandbox hoặc sản phẩm cuối cùng được chia sẻ an toàn.
Nguyên tắc đạo đức
Sử dụng thông tin cá nhân của khách hàng trong việc phân tích cần phải được thực hiện nghiêm túc và phải có nguyên tắc để đảm bảo an toàn. Việc này không chỉ đơn thuần là tuân thủ theo các yêu cầu pháp lý, mà các mô hình không nên có bất cứ loại sai lệch nào, và người tham gia cũng phải biết rõ dữ liệu của họ đang được sử dụng ở đâu.
Fuzzy Logic
Fuzzy Logic được sử dụng để tính khoảng cách giữa 2 string. Nó cũng giống cách sử dụng ký tự đại diện trong SQL và các biểu thức chính quy trong những ngôn ngữ khác.
Trong thế giới của khoa học dữ liệu, chúng ta có thể sử dụng thư viện Fuzzy Wuzzy Python trên các tập dữ liệu lớn.
GPU
Graphics Processing Units (GPUs) được thiết kế để xử lý hình ảnh, vì chúng được tạo thành từ nhiều lõi. Chúng có thể xử lý các lô dữ liệu khổng lồ và thực hiện cùng một nhiệm vụ nhiều lần, và đó cũng là lý do chúng có thể được sử dụng trong Khoa học dữ liệu.
Hadoop
Dự án Hadoop nguồn mở là một tập hợp các tiện ích tách riêng với Lưu trữ và Tính toán để chúng có thể được thu nhỏ hay mở rộng khi cần thiết.
Hadoop Distributed Files System (HDFS) – hệ thống phân phối file Hadoop – chia các file thành các khối logic cho lưu trữ, Spark, MapReduce hoặc công cụ khác có thể tiếp quản để xử lý (mình sẽ nói rõ hơn ở phần sau).
Fun fact: Hadoop là tên của con voi đồ chơi của con trai người tạo ra nó (Hình bên dưới).

Nhận diện hình ảnh
Tensorflow là một framework Machine Learning được sử dụng để train các mô hình dùng Neural Networks để nhận dạng hình ảnh.
Neural Networks chia input thành nhiều vector mà có thể dùng để giải thích, phân cụm và phân loại.
Jupyter Notebook
Jupyter Notebook chạy code, thực hiện phân tích thống kê và trình bày dữ liệu trực quan tất cả ở cùng một nơi. Nó hỗ trợ 40 ngôn ngữ và được đặt tên là Jupyter, giống như cách mà những quyển sổ của Galileo ghi lại các mặt trăng của Jupiter.
Kaggle
Nếu bạn đang tìm kiếm công cụ để luyện tập hoặc cần một bộ dữ liệu cho một dự án, thì Kaggle chính là nơi dành cho bạn. Luyện tập với một vài bộ data trên đó là bạn đã có thể tham gia các cuộc thi. Cộng đồng trên đây vô cùng thân thiện và bạn có thể sử dụng các công cụ mà bạn tự chọn.
Kỹ thuật hồi quy tuyến tính
Hồi quy là một trong những kỹ thuật thống kê được sử dụng trong Khoa học dữ liệu để tiên đoán một biến ảnh hưởng đến biến khác như thế nào. Hồi quy tuyến tính có thể sử dụng để phân tích mối quan hệ giữa các hàng xếp hàng trong siêu thị và sự thoả mãn của khách hàng, hay giữa nhiệt độ và giá bán kem.
Nếu bạn nghĩ có một mối quan hệ nào đó giữa 2 thứ nào đó, bạn có thể dùng hồi quy để chứng minh nó.
MapReduce
MapReduce là một phần tính toán của hệ sinh thái Hadoop. Khi chúng ta lưu trữ data có sử dụng HDFS, chúng ta có thể sử dụng MapReduce để xử lý sau đó. MapReduce xử lý data trong các khối logic, sau đó xử lý chúng song song trước khi tổng hợp các khối trở lại.
Natural Language Processing (NLP)
NLP như là cánh tay phải của AI, có liên quan đến việc làm thế nào máy tính có thể hiểu được ý nghĩa của ngôn ngữ con người nói. Nếu bạn đã từng dùng Suri, Cortana hay Grammarly, bạn đã gặp NLP rồi đấy.
Overfitting
Cả overfitting lẫn underfitting đều dẫn đến việc tiên đoán kém.
Overfitting – xảy ra khi một model quá phức tạp hoặc quá nhiễu. Model ghi nhớ và khái quát hoá tất cả dữ liệu đang train và không thể làm cho khớp giữa các tệp dữ liệu với nhau được.
Underfitting – xảy ra khi một model quá đơn giản và không có đủ thông số để nắm bắt xu hướng.
Pattern Recognition (Nhận dạng Pattern)
Nhận dạng Pattern được dùng để phát hiện sự tương đồng hoặc bất thường trong các tập dữ liệu. Ứng dụng thực tế của nó là trong nhận diện dấu vân tay, phân tích hoạt động địa chấn và nhận diện giọng nói.
Định lượng và định tính
Nếu bạn từng là kỹ sư và bước vào lĩnh vực Khoa học dữ liệu, có thể bạn sẽ cần kiểm tra lại số liệu thống kế của mình đấy. Tìm hiểu thêm về các kỹ năng cần thiết để chuyển vai trong cuộc phỏng vấn hấp dẫn này với Julia Silge của Stack Overflow.
Real Time
Apache Kafka là một hệ thống chính/phụ cho phép stream data từ log, hoạt động web và hệ thống giám sát.
Kafka được ứng dụng để:
- Tạo các đường stream data real-time đáng tin cậy giữa các hệ thống và ứng dụng.
- Tạo các ứng dụng stream real-time để biến đổi hoặc phản ứng lại các dòng data.
Spark
Apache Spark, giống MapReduce, là một công cụ để xử lý data.
Spark – có thể xử lý bộ nhớ trong nhanh hơn nhiều. Sẽ hữu ích nếu data cần được xử lý lặp đi lặp lại và trong thời gian thực.
MapReduce – Phải đọc và ghi vào đĩa nhưng có thể hạot động với các tập dữ liệu lớn hơn nhiều so với Spark.
Testing
AI có những ứng dụng thực tế trong Marketing với các đề xuất sản phẩm real-time, trong Sales với hệ thống VR giúp người mua hàng đưa ra quyết định và hỗ trợ khách hàng với NLP.
Và một ứng dụng mới phổ biến khác của AI đó là kiểm thử phần mềm. AI có thể được dùng để xếp ưu tiên thứ tự test, tự động hoá và tối ưu hoá các trường hợp và giúp QA bớt tẻ nhạt hơn.
Dữ liệu phi cấu trúc
Dữ liệu có cấu trúc có thể được lưu trữ trong CSDL quan hệ là các cột, hàng và bảng.
Khi trở thành dữ liệu phi cấu trúc gồm hình ảnh, video, text, việc lưu trữ sẽ thay đổi. Data Lakes có thể giúp bạn lưu trữ cả 2 loại mà chỉ với ít chi phí.
Data được lưu trữ ở đây được lấy ra và đọc khi có yêu cầu và cũng tổ chức dựa trên nhu cầu, điều này làm cho nó phổ biến với nhiều Data Scientist, những người thà giữ những điều kỳ quặc thay vì làm sạch và tổng hợp lại.
Khối lượng và vận tốc
Năm 2001 Big Data được định nghĩa bởi 3 chữ V:
- Volume (Khối lượng)
- Velocity (Vận tốc)
- Variety (Sự đa dạng)
Cho đến ngày nay thì có thêm một vài chữ V nữa là:
- Value (Giá trị)
- Veracity (Độ chính xác)
- Variability (Sự thay đổi)
- Visualisation (Hình dung)
Đã có tranh luận về việc liệu những thứ này có liên quan hay thực sự mô tả Big Data không. Nhưng nếu bạn đang nghiên cứu về ngành này thì chắc chắn chúng sẽ xuất hiện thôi.
Web Scraping
Các trường hợp cần quét web trong các dự án Big Data là:
- Kéo data từ các trang social media hoặc diễn đàn để phân tích cảm tính
- Lấy giá và sản phẩm để so sánh
- Phân tích nội dung site để xếp hạng và so sánh nội dung
Để bắt đầu sử dụng Python, cài đặt Scrapy để trích xuất dữ liệu có cấu trúc từ các trang web.
XML
Định dạng XML và JSON phổ biến trong Big Data vì giúp lưu trữ và vận chuyển dữ liệu. Để sử dụng với Python, hãy tìm hiểu trên ElementTree để phân tích XML và json để phân tích JSON
NumPy
NumPy được sử dụng trong Python để tích hợp với CSDL, thực hiện các tính toán khoa học và thao tác với các mảng.
ZooKeeper
Apache ZooKeeper luôn giữ cho các cluster chạy và available. Nó duy trì mạng bằng cách gửi tin nhắn qua lại và đảm bảo:
- Tính nhất quán tuần tự. Cập nhật từ khách hàng sẽ được áp dụng theo thứ tự mà chúng được gửi.
- Tính nguyên tố. Cập nhật thành công hoặc thất bại. Không có kết quả một phần.
- Hiển thị hình ảnh hệ thống đơn. Một khách hàng sẽ thấy cùng một chế độ xem bất kể máy chủ nào mà nó kết nối.
- Tính tin cậy. Khi bản cập nhật đã xong, nó sẽ tồn tại cho đến khi khách hàng ghi đè lên lại.
- Tính kịp thời. Quan điểm của khách hàng về hệ thống được đảm bảo cập nhật trong một thời gian nhất định.